Hello,
One of the things I enjoy superficially dabbling in is philosophy. Lately I’ve taken some time to watch some thought-provoking movies, as well as revisiting some old ones and it’s always interesting to explore the concepts presented in them. Especially considering that some people have taken inspiration from these to form philosophies they also follow in real life. The problem with these trains of thought though, are that in the end they are not useful. Anything I may have determined, even if shared with a friend will ultimately go nowhere and affect nothing. It is simply understanding by itself and for an utilitarian like myself, that is not acceptable. So, to help with that I’m making this blog in the hopes that someone will find it and read it and make use of it beyond… ideas in my head.

One of my personal favourites among movies would be Ghost in the Shell. Although I personally am not a huge anime fan, nor was I really in it for the action sequences or the porn, what is interesting about this series is it’s perspective of AI. As you know, I’m not a fan of movie’s tendencies to portray AI as evil or incapable of emotion. Considering the point that I have a vague idea of what we’d have to do to make an AI (tip: check resources on developmental psychology to understand how we humans develop intelligence), I would say we are at the state of technological development where we could start making true AIs. And therefore a fiction story like Ghost in the Shell becomes very interesting in exploring the concept of what it is that makes us… us.
Religious people might be quick to point out that at the core of each person is a soul, but I’m an atheist and I do not believe that is accurate. I do not think there is something special within us that makes us different from other living things or machines. Ghost in the Shell touches upon this by presenting the concept of a Ghost, blurring the lines between living things and machines (with cybernetics), but leaving the suspicion of the ambiguous Ghost that may or may not be present in AI.
The crushing truth about Ghost in the Shell is of course, that whether a Ghost inspires us or not, our ideas and everything we fight for in life, are ultimately not our own. We base them on things we learn from others, and therefore this begs the question: Who can be held responsible, for the consequences of ideas that are not our own? Is a hacked computer responsible for the information that was planted within it? Is a human responsible for having been deceived? Stand Alone Complex argues that we are not. In the end, we are all just nodes in the web, shuffling bits from one storage medium to the next, from the series, to my mind, to this blog, to your screen, to your mind. Our agency is an illusion, we feel compelled to act by the data made available to us.

Which brings me to the second movie with interesting philosophical themes: The Matrix. Partially based on Ghost in the Shell, this movie also explores the concept of agency. In a simulated world, all that there is to life is agency, your will to change the world around yourself. The first episode of the trilogy, which for many I imagine is the only movie you actually liked, is all about explaining to the main protagonist and therefore by extension to you, that you shouldn’t hold back and that you care capable of anything. Whether or not this actually applies to our reality is a subject of protracted debate, as: As you know, our reality isn’t actually physical in the conventional sense. All matter is just wave-forms, protuberances in the fabric of the universe — and therefore essentially data.
Regardless it would appear that a friend of mine, whom I would consider to be a bit of a mentor on life, has chosen to pick up the Neo-esque aesthetic, as well as I think some of the ideas presented there. His affinity to the Matrix philosophical content is not hard to understand, as he is someone who believes that being strictly rational and non-malevolent, has a potential to do a great amount of good in the world. To believe thinking in a certain way will affect the world, you ultimately have to believe that you can affect the world by force of will.
The human brain is optimised towards one function and that is processing social relationships. We as humans, like to pride ourselves by our intelligence, but we only focus on what is important to us: Technology and almost everything we do in life is focused around the relationships we have with other people. Even material wealth is ultimately only worth something to us, when compared to that of others. And therefore, as someone who can handle social relationships on a much more meta level than myself, my friend is someone I admire greatly. You could say my relationship to him is similar to the relationship most people have to god. When we end up in situations that appear chaotic to me, he usually has a plan and it usually involves teaching me something.
I wonder if his affinity for this aesthetic is also there to teach me something. The Matrix presents an epic story in which having a higher purpose can overcome systems of control designed to contain and maintain a society seeking to protect one’s own self-interest (even when this self-interest is selfless). In the end, reaching the desired outcome, may have you do the opposite of what you want. However what it takes is the agency to choose that outcome.

Something to think about.
LP,
Jure
 I think by now everyone has read that
I think by now everyone has read that 
 Even since I was a kid I remember enjoying old games like
Even since I was a kid I remember enjoying old games like  Similarly was another game, called XCOM. It was also a difficult combat game with no cheats, so it wasn’t something I could ever get into. But looking over my older brother’s shoulder, boy did the base building look appealing. A little immersion-breaking at times, when you had a missile silo 3 floors down from the surface with other buildings on top of it, but for me — I couldn’t care less how the game played, I loved the way the little discrete base modules looked like and how you could connect them together.
Similarly was another game, called XCOM. It was also a difficult combat game with no cheats, so it wasn’t something I could ever get into. But looking over my older brother’s shoulder, boy did the base building look appealing. A little immersion-breaking at times, when you had a missile silo 3 floors down from the surface with other buildings on top of it, but for me — I couldn’t care less how the game played, I loved the way the little discrete base modules looked like and how you could connect them together.






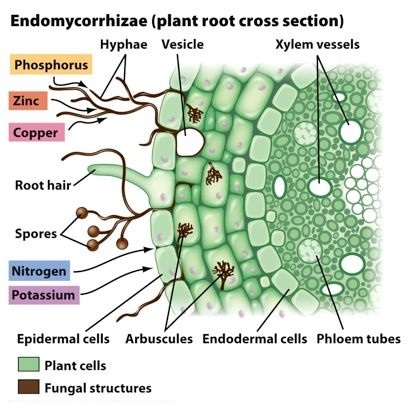 This makes fungi a lot better at certain tasks than both plants and animals. Notably in the case of plants, they are able to extract minerals and water out of soils that are otherwise either toxic or unavailable to the plant. The relationship between plant roots and fungi is very old and both plants and mycorrhizal fungi have specialised organs that serve to interface between the two species. The plant uses these organs to get nutrients and water from the fungus, and the fungus feeds of of hexoses, a special type of sugar produced by the plants specifically for the fungus.
This makes fungi a lot better at certain tasks than both plants and animals. Notably in the case of plants, they are able to extract minerals and water out of soils that are otherwise either toxic or unavailable to the plant. The relationship between plant roots and fungi is very old and both plants and mycorrhizal fungi have specialised organs that serve to interface between the two species. The plant uses these organs to get nutrients and water from the fungus, and the fungus feeds of of hexoses, a special type of sugar produced by the plants specifically for the fungus.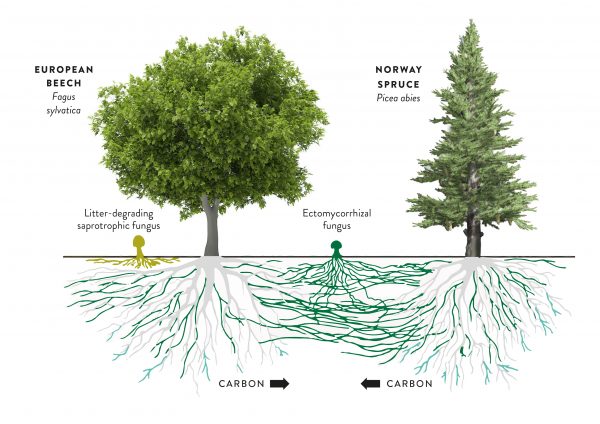 What I like to think (which is to say there is some foundation of this in the current research into mycorrhiza, but I am not a scientist) is that in nature, there are all of these different systems and what nature ends up using is whatever works best in a particular scenario. If different fungi are competing for plants and therefore only the most successful survive, some of the time this means that perfectly socialist networks will be prevalent. And since we have observed examples of this being the case, I would say it’s safe to say this kind of system can work. The plants and the fungi are able to determine this on their own without human interference, even in a system where abuse is quite possible and is probably even advantageous in some cases. That is, there are both plants and fungi that take advantage of the network, because they can. But it seems in the grand scheme of things, networks that do not have such individuals work better and out-compete networks that do contain exploitation.
What I like to think (which is to say there is some foundation of this in the current research into mycorrhiza, but I am not a scientist) is that in nature, there are all of these different systems and what nature ends up using is whatever works best in a particular scenario. If different fungi are competing for plants and therefore only the most successful survive, some of the time this means that perfectly socialist networks will be prevalent. And since we have observed examples of this being the case, I would say it’s safe to say this kind of system can work. The plants and the fungi are able to determine this on their own without human interference, even in a system where abuse is quite possible and is probably even advantageous in some cases. That is, there are both plants and fungi that take advantage of the network, because they can. But it seems in the grand scheme of things, networks that do not have such individuals work better and out-compete networks that do contain exploitation.






 There is a lot of mysticism online related to artificial intelligence. For a lot of people it’s little more than a science fiction level fascination and you can immediately tell this is the case based on their persistent and senseless recycling of Asimov’s laws, which originate from 60’s science fiction and are not applicable and never will be applicable to any real-world software program. I am not one of those people. I view AI from the perspective of a software developer and there is no place in my understanding of AI, for overly vague abstractions that are made up and have no translation in real life machine code.
There is a lot of mysticism online related to artificial intelligence. For a lot of people it’s little more than a science fiction level fascination and you can immediately tell this is the case based on their persistent and senseless recycling of Asimov’s laws, which originate from 60’s science fiction and are not applicable and never will be applicable to any real-world software program. I am not one of those people. I view AI from the perspective of a software developer and there is no place in my understanding of AI, for overly vague abstractions that are made up and have no translation in real life machine code.

